Fast websites are not created through optimization sprints or late-stage fixes — they are the result of architectural decisions made early and reinforced over time. When performance is treated as optional rather than structural, every new feature quietly makes the system slower.
Key Takeaways 👌
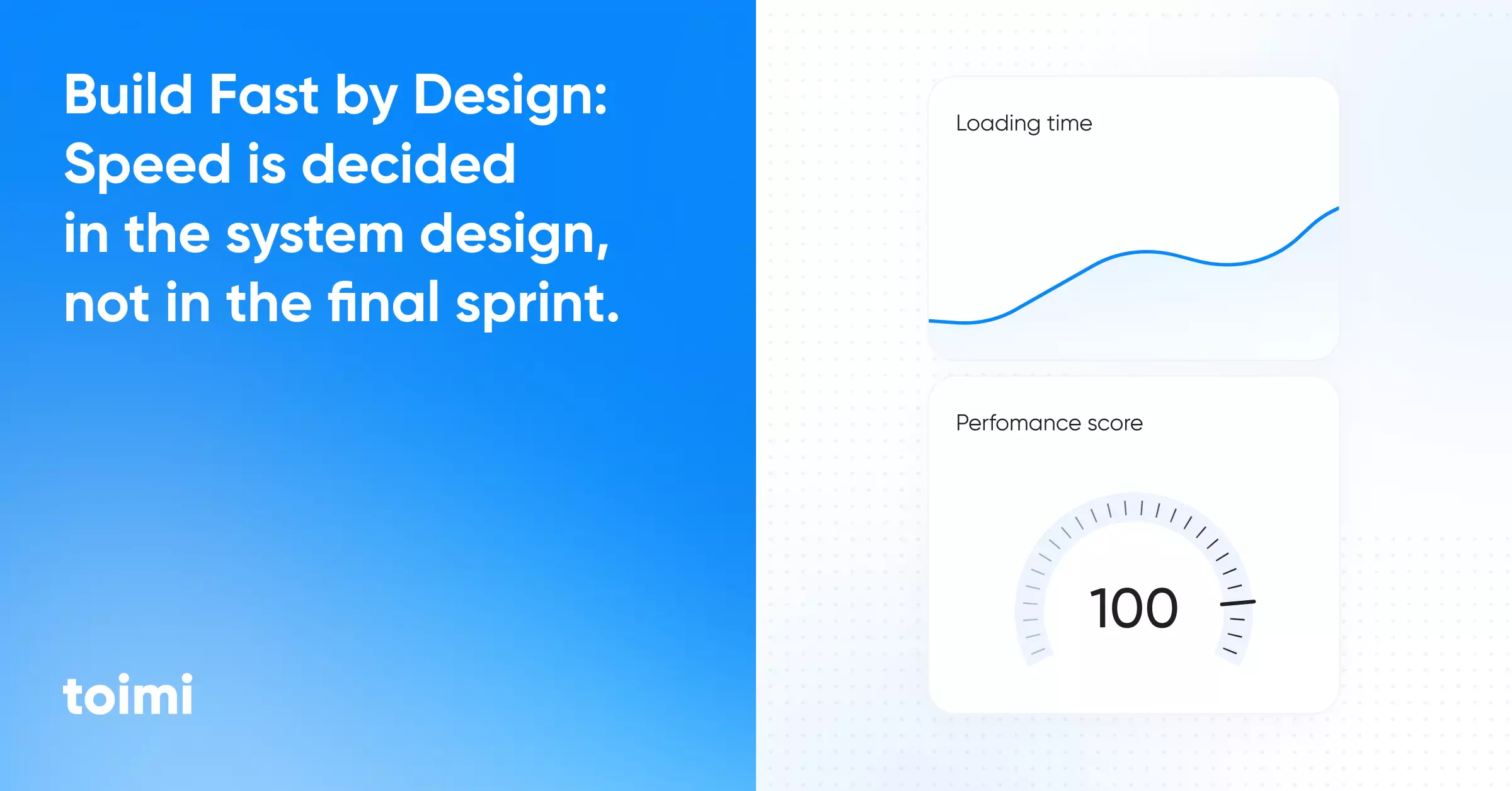
Website speed is an architectural outcome, not an optimization phase
Most performance problems originate in product, UX, and content decisions — not infrastructure
"Fast enough" for machines is not the same as "fast" for humans
Table of Contents
1. Why Website Speed Is a System Problem
How performance emerges from architecture, not optimization tricks.
2. What "Fast" Actually Means for Users and Businesses
Perceived speed, real metrics, and why milliseconds translate into trust and revenue.
3. Performance Starts Before Code
Product decisions, content strategy, and scope as the first performance constraints.
4. Frontend Architecture and Rendering Strategy
Rendering paths, JavaScript discipline, and how browsers really load pages.
5. Backend, Infrastructure, and Data Flow
APIs, databases, caching layers, and where latency actually accumulates.
6. Assets, Media, and Third-Party Dependencies
Images, fonts, scripts, and how external tools quietly destroy performance.
7. Core Web Vitals as Architectural Signals
Why LCP, INP, and CLS reflect system quality, not just tuning.
8. Performance Budgets and Continuous Control
How fast websites stay fast over months and years.
9. Common Performance Anti-Patterns
The decisions that make websites slow — even when teams "care about speed."
10. A Practical Framework for Building and Maintaining Fast Websites
How to evaluate, prioritize, and evolve performance without heroics.
1. Why Website Speed Is a System Problem
How performance emerges from architecture, not optimization tricks
Website performance is usually discussed as a technical concern, but in practice it is a systemic one. Slow websites are rarely the result of a single mistake, misconfiguration, or overlooked optimization. Instead, they emerge from a sequence of decisions made across product, design, content, and engineering — often by different people, at different times, with different priorities. By the time performance becomes visibly problematic, the causes are already deeply embedded in the structure of the system.
Performance starts at the architecture stage — not as a post-launch optimization. The web development process builds performance budgets into Stage 2.
A bad system will beat a good person every time.
— Don Norman, author
Most teams encounter performance reactively. Speed becomes a topic only after user complaints, declining conversion rates, or SEO issues surface. At that point, performance work is framed as a remediation effort: audits are run, assets are compressed, scripts are deferred, and hosting is upgraded. These steps can temporarily improve metrics, but they rarely address the underlying issue. The system continues to evolve in the same way, and performance degrades again as soon as new features, content, or integrations are added.
The core misunderstanding lies in treating performance as an attribute of implementation rather than an outcome of architecture. Implementation-level optimizations assume that the system itself is sound and only needs tuning. Architectural thinking starts from the opposite assumption: that complexity is inevitable, and without constraints, it will accumulate faster than performance fixes can compensate for.
Performance architecture does not exist in isolation from how a website is actually built. Choices around structure, rendering strategy, and data flow are deeply tied to the fundamentals of web development, especially when speed is treated as a system-level constraint rather than a post-launch fix.
From this perspective, performance does not "break." It emerges predictably from how the system is allowed to grow.
Optimization Thinking vs Architectural Thinking
The difference between these two approaches becomes clearer when examined side by side.
Aspect |
Optimization mindset |
Architectural mindset |
When speed is addressed |
After problems appear |
Before problems can emerge |
Scope of action |
Local, isolated fixes |
System-wide constraints |
Primary tools |
Audits, plugins, tuning |
Structure, limits, governance |
Typical interventions |
Minification, compression, deferral |
Dependency control, scope discipline |
Long-term effect |
Temporary improvement |
Predictable, stable performance |
Common failure mode |
Performance regression |
Managed complexity |
Optimization thinking focuses on correcting symptoms. Architectural thinking focuses on preventing them.
Both approaches have their place, but confusing one for the other leads to chronic performance problems. Optimization is necessary in any real system, but it cannot compensate for unchecked structural growth. When performance relies entirely on continuous tuning, it becomes fragile. Every new feature increases the maintenance burden, and speed turns into a constant negotiation rather than a property of the system.
Why Performance Problems Appear "Suddenly"
One of the reasons performance issues feel unexpected is that early-stage websites are almost always fast. They have limited content, minimal integrations, and straightforward logic. Speed feels natural and effortless, which reinforces the belief that performance can always be recovered later if needed.
This belief is misleading. Performance debt accumulates quietly. Each additional script, design enhancement, personalization rule, tracking tool, or content block introduces marginal overhead. Individually, these costs are small enough to ignore. Collectively, they reshape the system's behavior.
At a certain point, optimization efforts stop producing meaningful results. The system becomes resistant to improvement because the problem is no longer local. Latency is spread across rendering, data fetching, client-side logic, and third-party dependencies. Fixing one layer exposes bottlenecks in another. Teams begin to chase metrics instead of addressing structure.
This is why performance problems often appear "all at once," even though their causes have been accumulating for months or years.
Performance as an Architectural Constraint
Fast websites treat performance as a constraint, not a goal. Constraints influence decisions automatically. When speed is considered a non-negotiable property of the system, teams are forced to evaluate trade-offs earlier and more honestly.
Questions shift from "Can we make this work?" to "Is this worth the cost it introduces?" Feature scope, interaction complexity, and dependency choices are evaluated not only by business value, but by their impact on system behavior over time. This does not eliminate complexity, but it ensures that complexity is introduced deliberately rather than accidentally.
In well-architected systems, performance is not maintained through heroics or constant firefighting. It is preserved because the system is designed to resist unnecessary growth. Limits are explicit, responsibilities are clear, and speed remains predictable even as the website evolves.
Fast websites are not optimized into existence.
They are structured that way from the start.

2. What "Fast" Actually Means for Users and Businesses
Speed is often discussed as a technical property, measured in milliseconds and scores. In reality, speed is an experiential quality. Users do not perceive metrics; they perceive responsiveness, stability, and effort. A website can meet formal performance thresholds and still feel slow, unreliable, or exhausting to use. Understanding this gap is critical, because architectural decisions should optimize for human perception first, not tooling dashboards.
Perceived Speed vs Measured Speed
Measured speed describes what happens in the browser and network. Perceived speed describes what happens in the user's mind. These two are related, but not identical.
A page can technically load quickly while still feeling slow if the user cannot immediately understand what to do, if key content appears late, or if interactions feel delayed or unstable. Conversely, a page with heavier technical requirements can feel fast if it provides early visual feedback, stable layout, and predictable interaction patterns.
Performance is not about how fast your site is, it's about how fast your site feels.
— Steve Souders, computer scientist and author
Why perception dominates behavior
Users do not wait for pages to fully load before forming judgments. Studies consistently show that trust, confidence, and willingness to engage are shaped in the first moments of interaction. If the system appears hesitant or chaotic, users subconsciously assume it will continue behaving that way.
Perceived speed influences:
- whether users continue exploring or abandon early,
- how confident they feel entering data or making decisions,
- how "professional" or "reliable" the business behind the site appears.
This is why performance architecture cannot be reduced to raw load times. It must account for sequencing, feedback, and cognitive load.
The illusion of speed
Fast systems often rely on illusion — not deception, but prioritization. Showing meaningful content early, reserving space to avoid layout shifts, and responding instantly to user input all create the impression of speed, even if background work continues.
Architecturally, this means designing loading paths intentionally rather than letting them emerge accidentally. What renders first, what blocks interaction, and what can be deferred are not technical afterthoughts. They are product decisions.
Performance as a Trust Signal
Speed is not only about convenience. It is about trust.
When a website responds instantly and predictably, users assume competence. When it hesitates, jumps, or behaves inconsistently, users assume risk. This is especially true in contexts involving money, personal data, or complex decisions.
Corporate websites are especially sensitive to performance degradation because they tend to grow incrementally over years. Without deliberate architectural decisions during corporate website development, speed erodes quietly as new sections, scripts, and integrations accumulate.
People don't trust software that behaves inconsistently.
— Jared Spool, researcher and author
Latency as perceived risk
Even small delays introduce doubt. Users may not consciously notice a 300–500ms delay, but they feel the hesitation. Over time, these micro-frictions accumulate into a general sense that the system is fragile or unreliable.
This is why performance issues rarely show up as explicit complaints. Users don't say "this site has poor interaction latency." They say things like:
- "It feels clunky."
- "I don't trust it."
- "I'd rather use something else."
From a business perspective, these reactions directly affect conversion, retention, and brand perception — even when the product itself is competitive.
Stability matters as much as speed
A fast interface that shifts unexpectedly, reflows content, or changes state without clear feedback erodes trust just as quickly as a slow one. Visual stability is a core part of perceived performance. Users need to feel that what they see can be relied upon.
Architecturally, this places constraints on how content is loaded, how layout is structured, and how asynchronous behavior is handled. Performance is not just about how fast something appears, but about whether it appears where and when users expect it to.
Landing pages expose performance problems faster than almost any other format. In landing page development, even small delays in first interaction or visual stability directly affect conversion, making architectural discipline immediately visible in results.
Business Impact of Performance Beyond Conversion
Performance is often justified in terms of conversion rates, but its impact is broader and more structural. Speed affects how users explore, how long they stay, and how much complexity they are willing to tolerate.
Performance shapes user behavior
Fast systems invite exploration. Slow systems discourage it. When interaction feels effortless, users are more willing to click deeper, compare options, and engage with secondary content. When friction is present, users minimize effort and leave earlier.
This has cascading effects:
- reduced depth of engagement,
- weaker content discovery,
- lower perceived value of advanced features.
Over time, this skews product analytics and can lead teams to make incorrect assumptions about what users actually want.
Speed as a scaling factor
As websites grow — more pages, more personalization, more integrations — performance becomes a multiplier. A slow system scales poorly: each new addition makes everything worse. A fast system scales more gracefully because its architecture absorbs growth without proportional degradation.
This is why performance architecture is not just a technical concern, but a business enabler. It determines how much complexity a website can support before it becomes self-defeating.
Why Metrics Alone Are Not Enough
Metrics like Core Web Vitals are valuable, but they are indicators, not explanations. They tell you what is happening, not why. Treating them as targets rather than signals leads to shallow fixes that miss deeper issues.
Architectural performance work uses metrics diagnostically. It asks:
- which decisions produce these results,
- which constraints are missing,
- and how future growth will affect the system.
Without that lens, teams optimize numbers while the underlying structure continues to deteriorate.
Redefining "Fast" for Architecture
From an architectural standpoint, a fast website is one that:
- responds immediately to user intent,
- remains stable under change,
- degrades gracefully under load,
- and maintains these properties as it evolves.
This definition shifts performance from a finishing step to a foundational requirement. It reframes speed as something that must be designed into the system — not chased after it escapes.
3. Performance Starts Before Code
Most performance problems are already locked in before a single line of code is written. By the time engineering begins implementation, the system is often carrying assumptions that predetermine how heavy, fragile, and slow it will eventually become. These assumptions usually originate in product scope, content strategy, and UX structure — areas that are rarely evaluated through a performance lens.
Many performance issues originate before implementation, at the UX and product design stage. When interface complexity, interaction density, or content hierarchy are defined without performance constraints, engineering teams inherit problems that are difficult to reverse later.
Speed is not something development teams "add" later. It is something they inherit from earlier decisions.
The earliest and most consequential performance decision is scope. Every feature, page, interaction, and state that is considered "non-negotiable" adds surface area to the system. Teams often underestimate how quickly this surface area compounds. A seemingly simple requirement — such as supporting multiple content types, user roles, or personalized states — multiplies rendering paths, data dependencies, and conditional logic. Each of these layers introduces potential latency and coordination cost.
Crucially, scope is often expanded without clear ownership. Product requirements grow through stakeholder requests, marketing needs, compliance considerations, and edge cases, but few teams are responsible for evaluating how these additions affect system behavior over time. Performance degrades not because any single request is unreasonable, but because no one is tasked with saying when the system is becoming too complex for its original architecture.
Content strategy plays a similarly underappreciated role. Content is frequently treated as inert payload — text, images, media — rather than as an active part of the system. In reality, content structure determines page weight, rendering order, and interaction cost. Rich layouts, embedded media, dynamic blocks, and personalization logic all influence how quickly meaningful content appears and how stable it remains during load.
When content is created without structural discipline, performance becomes unpredictable. Pages with similar templates behave differently. Loading patterns vary across sections. Teams resort to per-page fixes instead of addressing systemic issues. At that point, performance work becomes reactive by necessity.
UX structure further amplifies these effects. Navigation depth, conditional flows, and interface density directly affect how much work the browser must do before users can act. Complex layouts with nested components, excessive state management, or heavy client-side logic often emerge from well-intentioned design decisions that prioritize flexibility or expressiveness over restraint.
This is where performance debt begins to crystallize. Design systems grow without performance budgets. Interaction patterns are added because they "feel modern," not because they serve a clear purpose. Over time, the interface becomes harder to reason about — both for users and for the system itself.
Importantly, none of these decisions are inherently wrong. The issue is not ambition, but the absence of constraints. When performance is not treated as a first-class requirement during discovery and design, every downstream choice defaults toward richness rather than efficiency. Engineering teams are then asked to make that richness fast, even when the underlying structure resists optimization.
By the time code is written, many architectural limits are already fixed. Rendering strategies, data dependencies, and layout complexity are constrained by earlier commitments. Developers can optimize around the edges, but they cannot easily remove complexity that has been embedded into the product's definition.
This is why performance architecture must begin before technical execution. It requires product, design, and content teams to treat speed as a shared responsibility rather than a downstream concern. Decisions about what the system does, how it is structured, and what it prioritizes are also decisions about how fast it can be — now and in the future.
Fast websites are not the result of exceptional engineering alone. They are the result of restraint exercised early, clarity enforced consistently, and complexity introduced only when it is earned.
Performance architecture becomes much easier to manage when decisions are made deliberately at each stage of website development, rather than retrofitted after launch.
4. Frontend Architecture and Rendering Strategy
Frontend architecture is where performance becomes tangible. Unlike backend latency or infrastructure limits, frontend decisions directly shape what users see, when they can act, and how stable the interface feels while the system is still working. Many performance problems that appear "technical" at this layer are in fact architectural consequences of how rendering responsibility is distributed between the browser, the network, and JavaScript.
A fast frontend is not defined by frameworks or tools. It is defined by how deliberately rendering work is sequenced, constrained, and deferred.
Many teams postpone performance work until a redesign feels unavoidable. Understanding when redesign is necessary — and when it isn't — helps avoid both premature visual refreshes and dangerously delayed structural fixes.
If you ship too much JavaScript, everything else becomes slow.
— Alex Russell, influential software engineer and web platform architect
Rendering Is the Critical Path
From the user's perspective, a page is usable when meaningful content appears and interaction becomes possible. From the browser's perspective, this requires resolving a chain of dependencies: HTML parsing, CSS evaluation, JavaScript execution, layout calculation, and painting. Frontend architecture determines how long this chain is — and how much of it blocks progress.
Modern websites often overestimate the browser's capacity to multitask. While browsers are sophisticated, rendering remains a sequential process in many critical areas. Heavy JavaScript execution, large layout trees, and excessive reflows compete for the same limited resources. When architecture ignores this reality, performance degrades regardless of infrastructure quality.
Server-Side vs Client-Side Rendering
One of the most consequential frontend decisions is where rendering happens. This choice affects not only speed, but predictability, stability, and long-term maintainability.
Server-side rendering (SSR)
With server-side rendering, the browser receives pre-rendered HTML that can be displayed immediately. This improves initial load perception and reduces dependency on client-side execution. SSR is especially effective for content-heavy pages, SEO-critical routes, and first-time visits.
However, SSR introduces its own trade-offs. It increases server workload, complicates caching strategies, and requires careful coordination between server and client states. Poorly implemented SSR can shift bottlenecks rather than remove them.
Client-side rendering (CSR)
Client-side rendering shifts responsibility to the browser. The initial HTML is minimal, and most content appears only after JavaScript executes. This approach can work well for highly interactive applications with authenticated users, where initial load is less critical than ongoing responsiveness.
The downside is obvious: CSR makes performance highly sensitive to JavaScript size, execution time, and device capability. On slower devices or constrained networks, CSR architectures often feel sluggish even when metrics look acceptable.
Hybrid approaches
Most modern architectures land somewhere in between. Hybrid rendering strategies attempt to combine early server-rendered content with progressive client-side enhancement. When done well, this balances perceived speed with interactivity. When done poorly, it creates duplicated work, hydration mismatches, and unpredictable behavior.
The key is not choosing a fashionable approach, but aligning rendering strategy with actual usage patterns and constraints.
JavaScript as a Performance Liability
JavaScript is both powerful and dangerous. It enables rich interaction, but it also competes directly with rendering and input handling. Every script added to a page increases the risk of blocking, jank, or delayed responsiveness.
Execution cost matters more than file size
Teams often focus on bundle size alone, but execution cost is frequently the real bottleneck. Parsing, compiling, and executing JavaScript consumes CPU time — especially on mobile devices. A moderately sized bundle with heavy runtime logic can be more damaging than a larger but simpler one.
Architecturally, this means questioning not just how much JavaScript is shipped, but what it does and when it runs.
Hydration and interactivity timing
Hydration is a common source of performance confusion. Content may appear quickly, but remain unresponsive until JavaScript finishes attaching event handlers and state. Users perceive this as lag or broken interaction.
Frontend architecture should prioritize interactivity paths deliberately. Not all elements need to become interactive at once. Deferring non-essential hydration can dramatically improve perceived responsiveness.
Layout Complexity and Stability
Layout decisions have performance implications beyond aesthetics. Deeply nested DOM trees, conditional rendering, and dynamic layout shifts increase layout calculation cost and undermine stability.
Complex layouts also magnify the cost of change. Small updates can trigger large reflows, affecting unrelated parts of the page. Over time, this leads to fragile interfaces where performance regressions appear unexpectedly.
Architecturally sound frontends favor simpler, predictable layout structures. Stability is not just a UX concern; it is a performance strategy.
When performance feels inconsistent rather than uniformly slow, the cause is often structural. A focused UX/UI audit helps identify where interaction patterns, layout decisions, or user flows are adding unnecessary load and blocking responsiveness.
Frontend Architectural Trade-offs in Practice
The table below illustrates how common frontend choices affect performance characteristics.
Architectural choice |
Performance benefit |
Performance risk |
Server-side rendering |
Faster initial content |
Higher server load |
Client-side rendering |
Rich interactivity |
Slow first paint |
Heavy component abstraction |
Code reuse |
Increased render cost |
Dynamic layouts |
Flexibility |
Layout instability |
Rich animations |
Visual polish |
Main thread blocking |
Minimal JS with progressive enhancement |
Predictable speed |
Reduced expressiveness |
There is no universally correct configuration. Every frontend architecture reflects trade-offs. What matters is whether those trade-offs are intentional and aligned with performance goals.
Frontend Architecture as a Long-Term Commitment
Frontend architecture is difficult to change once a system grows. Rendering strategy, component structure, and state management patterns tend to persist because so much depends on them. This makes early decisions disproportionately important.
Fast websites do not rely on constant tuning at the frontend layer. They rely on architectural restraint: limited responsibility for JavaScript, predictable rendering paths, and clear separation between what must happen immediately and what can wait.
When frontend architecture is treated as a performance system rather than a styling concern, speed stops being fragile and starts being repeatable.
In mature products, performance issues are often symptoms of outdated assumptions. At that point, incremental fixes may no longer be enough, and a redesign becomes necessary to realign structure, rendering strategy, and user behavior with current needs.
5. Backend, Infrastructure, and Data Flow
When frontend performance issues are addressed, teams often discover that speed does not improve as much as expected. Pages render faster, interactions feel lighter, yet the system still hesitates under load or becomes inconsistent as traffic grows. This is usually the point where performance is misdiagnosed as a frontend problem when, in reality, latency is being generated deeper in the system.
Backend architecture and data flow determine how much work is required before the frontend can even begin to respond. Poorly structured backend systems force the interface to wait, retry, or compensate for uncertainty. Over time, frontend complexity grows not because of design ambition, but because the backend cannot deliver data predictably.
Architecture is about the important stuff. Whatever that is.
— Martin Fowler, software engineer and author
Performance and security are often treated separately, but both depend on predictable system behavior. Overloaded or unstable systems tend to introduce security shortcuts just as often as performance regressions.
Latency Is Accumulative, Not Local
Backend performance is rarely determined by a single slow operation. Instead, latency accumulates across multiple steps: request routing, authentication, business logic, database queries, and downstream service calls. Each step may appear acceptable in isolation, but together they produce noticeable delay.
The architectural mistake most teams make is optimizing these steps independently. A faster database query does not help if requests still queue behind authorization checks. Efficient APIs do not improve perceived speed if responses are serialized through unnecessary layers. Performance emerges from how these components interact, not how fast each one is on its own.
This is why backend systems that scale poorly often look "fine" in early testing. Low traffic hides coordination costs. As usage grows, the architecture reveals its true behavior.
Frontend performance is tightly coupled with how data is delivered. Poorly structured API development forces interfaces to orchestrate multiple requests, increasing latency and pushing complexity into the browser where resources are limited.
API Design as a Performance Constraint
APIs define how data moves through the system. Their structure determines not only flexibility, but also latency and coupling. APIs that mirror internal data models too closely tend to expose complexity directly to the frontend. As a result, the frontend is forced to orchestrate multiple requests, handle partial failures, and assemble state manually.
This pattern increases both network overhead and cognitive load. Each additional request adds latency, and each dependency increases the chance of inconsistency. Over time, frontend teams compensate by caching aggressively, duplicating logic, or prefetching data speculatively — all of which introduce new performance risks.
Architecturally sound APIs prioritize coherence over completeness. They deliver data in shapes that align with actual usage patterns, even if that means duplicating or aggregating information server-side. This shifts complexity away from the browser, where resources are constrained and variability is high.
Data Modeling and Its Hidden Cost
Data models are often treated as neutral representations of reality. In practice, they encode assumptions that directly affect performance. Highly normalized schemas optimize storage and integrity, but often require multiple joins or queries to assemble meaningful responses. Over time, this increases response latency and complicates caching.
Conversely, denormalized or purpose-built read models trade elegance for speed. They accept redundancy in exchange for predictability. Neither approach is inherently correct, but the choice must align with how data is consumed.
Problems arise when data models are designed without considering access patterns. As features are added, queries become more complex, response times grow, and performance issues are addressed through ad hoc fixes rather than structural change. At that point, the data model itself becomes a performance bottleneck.
Infrastructure Does Not Fix Architectural Debt
When backend performance degrades, infrastructure upgrades are often proposed as the solution. More powerful servers, additional instances, or managed services can temporarily mask inefficiencies. They rarely resolve them.
Scaling infrastructure without addressing architectural issues increases cost and operational complexity. Latency caused by excessive coordination, synchronous dependencies, or inefficient data access does not disappear simply because more resources are available. In some cases, it becomes harder to diagnose as the system grows more distributed.
Infrastructure should support architecture, not compensate for it. Well-architected systems benefit from scaling because their bottlenecks are understood and controlled. Poorly architected systems scale unpredictably, with performance degrading in non-linear ways.
Caching as an Architectural Decision
Caching is often introduced reactively, as a way to relieve pressure on slow components. While caching can dramatically improve performance, it also introduces consistency challenges and failure modes that must be managed deliberately.
Effective caching strategies are designed early. They define what data can be cached, for how long, and at which layer. Ad hoc caching decisions made under pressure tend to produce fragmented behavior: some users see fresh data, others see stale data, and debugging becomes difficult.
From an architectural standpoint, caching is not an optimization trick. It is a commitment to specific data freshness guarantees. Making that commitment explicit is what allows caching to improve performance without undermining trust.
Data Flow as the Backbone of Performance
Ultimately, backend performance depends on how data flows through the system. Clear ownership of responsibilities, predictable request paths, and minimal cross-dependencies create systems that respond consistently under load. Ambiguous boundaries and implicit coordination create latency that is hard to predict and harder to fix.
Fast websites are supported by backends that do less, not more. They avoid unnecessary work, minimize synchronous dependencies, and expose clear, stable interfaces to the frontend. This does not eliminate complexity, but it ensures that complexity is contained and managed.
When backend architecture aligns with frontend expectations, performance work becomes additive rather than corrective. When it does not, frontend optimization turns into an endless attempt to compensate for systemic delay.
In complex platforms and online services, performance failures rarely come from a single slow endpoint. They emerge from coordination overhead between services, permissions, personalization, and real-time data flows that were not designed with speed as a constraint.
6. Assets, Media, and Third-Party Dependencies
Even well-architected systems are frequently undermined by what they load. Assets and third-party dependencies represent one of the most common sources of performance decay because they are often treated as peripheral concerns. Images, fonts, analytics scripts, marketing tools, and embedded services are added incrementally, usually by different teams, with limited visibility into their cumulative cost.
Unlike core application logic, these elements are rarely owned by a single discipline. As a result, their impact compounds quietly until performance problems become systemic.
Assets Are Not Passive Payloads
Images, fonts, and media are often described as static resources, but from a performance perspective they are active participants in rendering. Large images block meaningful paint. Web fonts delay text rendering or cause layout shifts. Video embeds introduce heavy scripts even when not immediately visible.
The architectural mistake is treating assets as content rather than as execution cost. Each asset affects:
- network bandwidth consumption,
- render timing,
- layout stability,
- and CPU usage for decoding and painting.
When asset strategy is undefined, teams default to convenience. Designers export at maximum quality "just in case." Content teams embed rich media without performance budgets. Developers compensate with lazy loading and compression — often too late to preserve early interaction quality.
Media Strategy as a Performance Decision
Media strategy is rarely documented, yet it defines a large portion of page weight and load behavior. Decisions about image formats, responsive sizing, video delivery, and fallback behavior determine whether pages scale gracefully across devices or degrade sharply under constraint.
A disciplined media strategy prioritizes:
- responsive assets matched to viewport and density,
- modern formats with clear fallback paths,
- explicit loading priorities for critical visuals,
- and strict limits on autoplay or background media.
Without these constraints, media becomes the fastest-growing source of performance debt.
Fonts and the Cost of Brand Expression
Typography is a core part of brand expression, but web fonts are among the most underestimated performance liabilities. Multiple font families, weights, and subsets increase request count and block rendering paths. Poorly configured font loading leads to invisible text, reflows, or inconsistent rendering across devices.
The architectural issue is not the use of custom fonts, but the absence of clear rules. When brand expression is not reconciled with performance constraints, typography becomes a silent bottleneck. Well-performing systems treat fonts as part of performance architecture, not as decorative assets.
Third-Party Scripts: Performance by Proxy
Third-party dependencies are especially dangerous because their cost is externalized. Analytics, tag managers, A/B testing tools, chat widgets, heatmaps, personalization engines, and ad trackers all introduce JavaScript that executes outside the team's direct control.
Each script adds:
- network requests,
- execution overhead,
- potential blocking,
- and failure points that are difficult to diagnose.
What makes third-party scripts particularly harmful is their tendency to bypass architectural constraints. They are often injected globally, load early, and execute synchronously by default. Even when individually "lightweight," their combined effect can dominate main-thread activity.
Cumulative Cost and Invisible Coupling
The true danger of unmanaged assets and dependencies lies in their interaction. Media assets delay rendering. Fonts block text. Scripts compete for execution. Each addition changes the timing of others. Performance regressions emerge not from a single decision, but from invisible coupling between components.
This is why performance audits often identify "death by a thousand cuts." No single asset looks excessive. No single script appears catastrophic. Yet together, they reshape the critical rendering path in ways that are hard to reverse.
Comparative Impact of Common Asset and Dependency Choices
The table below illustrates how typical asset and dependency decisions affect performance characteristics.
Element |
Common decision |
Performance impact |
Architectural risk |
Images |
High-resolution defaults |
Increased LCP |
Bandwidth dependency |
Video embeds |
Early loading |
Main-thread blocking |
Poor first interaction |
Web fonts |
Multiple families/weights |
Render delay, CLS |
Layout instability |
Analytics scripts |
Global synchronous load |
CPU contention |
Unpredictable latency |
Tag managers |
Uncontrolled growth |
Script cascade |
Hidden regressions |
Third-party widgets |
Always-on integration |
Execution spikes |
External failure modes |
These risks are not theoretical. They are among the most common reasons fast systems slow down over time despite unchanged core architecture.
Treating Assets and Dependencies as Architecture
Fast websites treat assets and third-party dependencies as architectural elements with explicit constraints. They define what is allowed, when it may load, and how its cost is justified. Performance budgets are applied not only to code, but to everything that executes or renders.
This does not require eliminating rich media or external tools. It requires acknowledging that every external dependency is a trade-off. When those trade-offs are made deliberately, performance remains predictable. When they are made opportunistically, speed degrades invisibly until correction becomes expensive.
Assets and integrations do not slow websites by accident.
They slow them because no one is responsible for saying "enough."
7. Core Web Vitals as Architectural Signals
Core Web Vitals are often treated as performance targets, something to be optimized until a score turns green. This framing misses their actual value. Core Web Vitals do not describe what to optimize; they describe where architecture is failing. Each metric reflects a structural property of the system and reveals how decisions made across product, design, and engineering manifest in real user experience.
Performance is a UX metric — a 3-second load time causes 53% abandonment. Learn more in our UX/UI design guide.
Why Core Web Vitals Exist
Search engines did not introduce Core Web Vitals to encourage technical perfection. They exist because performance problems consistently correlate with poor user experience and reduced trust. Instead of relying on abstract notions of "fast," Core Web Vitals capture how websites behave under real-world conditions: slow devices, unstable networks, and partial attention.
Architecturally, these metrics act as pressure tests. They expose where systems are fragile, overloaded, or poorly sequenced. Treating them as checkboxes misses their diagnostic purpose.
Performance architecture directly affects visibility. Search engines increasingly treat speed and stability as signals of quality, which makes performance an essential part of modern SEO rather than a purely technical concern.
Largest Contentful Paint (LCP): Content Priority and Data Flow
What LCP really measures
LCP measures how long it takes for the largest meaningful piece of content to become visible. This is not about total load time, but about whether users see something useful early enough to trust the system.
Architecturally, LCP is affected by:
- how content is prioritized,
- where data is fetched,
- and how rendering is blocked or delayed.
Slow LCP often indicates that critical content is competing with non-essential work. Heavy assets, late data availability, or unnecessary client-side processing push meaningful content down the rendering queue.
Structural causes of poor LCP
Poor LCP is rarely caused by a single large image. More often, it emerges from layered delays: synchronous scripts, blocking stylesheets, inefficient data aggregation, or server response time variability. Fixing LCP sustainably requires rethinking what the system considers "critical," not just compressing assets.
Interaction to Next Paint (INP): System Responsiveness Under Load
Why INP replaced FID
INP focuses on responsiveness across the entire user session rather than just the first interaction. This shift reflects a deeper architectural truth: performance problems accumulate as users interact with the system.
INP measures how quickly the interface responds after a user action. High INP values indicate that the main thread is busy, often due to excessive JavaScript execution, complex state updates, or inefficient event handling.
INP as a signal of architectural stress
From an architectural standpoint, poor INP suggests that the frontend is doing too much synchronously. Business logic leaks into the client, state management grows unbounded, or third-party scripts compete for execution time. These issues are structural. They cannot be fixed reliably without reducing responsibility at the interaction layer.
Cumulative Layout Shift (CLS): Stability and Predictability
Why layout stability matters
CLS measures how much content moves unexpectedly during load or interaction. While often framed as a visual annoyance, layout instability undermines trust. Users hesitate when interfaces shift beneath them, especially in transactional contexts.
Architecturally, CLS reflects how layout decisions are coordinated. Undefined dimensions, late-loading assets, injected content, and asynchronous UI updates all contribute to instability.
CLS as an architectural discipline problem
Stable layouts require explicit planning. Space must be reserved, content must be predictable, and dynamic elements must respect constraints. When CLS is high, it often indicates that the system prioritizes flexibility over predictability — a trade-off that favors developer convenience at the expense of user confidence.
Reading Metrics as Symptoms, Not Goals
Treating Core Web Vitals as targets leads to shallow fixes: deferring scripts indiscriminately, hiding content until load completes, or gaming measurements without improving experience. These approaches may improve scores temporarily while leaving architectural weaknesses intact.
Used correctly, Core Web Vitals guide inquiry. They help teams ask better questions about responsibility, sequencing, and constraints. When metrics worsen, the response should not be "optimize harder," but "what changed in the system?"
Architectural Interpretation Over Metric Chasing
Fast websites maintain healthy Core Web Vitals not because they chase numbers, but because their architecture naturally produces stable, responsive behavior. Content is prioritized intentionally. Interaction is lightweight. Layout is predictable. Dependencies are constrained.
When architecture aligns with these principles, Core Web Vitals become confirmation rather than pressure. They reflect a system that behaves well by design, not one that survives through constant tuning.
8. Performance Budgets and Continuous Control
Performance rarely collapses because of a single bad decision. It degrades because there is nothing in the system that prevents gradual erosion. New features are added, dependencies accumulate, content grows richer, and interactions become more complex — all without a shared mechanism that enforces limits. Performance budgets exist to solve exactly this problem.
A performance budget is not a target to hit once. It is a constraint that governs how the system is allowed to evolve. Without such constraints, speed becomes optional by default, and optional qualities are always sacrificed under pressure.
There is no silver bullet.
— Fred Brooks, computer scientist and software engineer
Why Performance Regressions Are Almost Always Incremental
Most teams experience performance regression as something sudden: "the site used to be fast, now it's slow." In reality, the regression usually happens through dozens of small changes that individually seem harmless. A tracking script here, a richer hero section there, a new personalization rule, a heavier component abstraction. Each change adds a small amount of work to the system, and none of them feel large enough to block delivery.
The problem is that performance does not degrade linearly. Systems tolerate complexity up to a point, and then small additions suddenly have outsized effects. Rendering paths become congested, main-thread execution spikes, and latency becomes visible to users. By the time this threshold is crossed, reversing it requires structural work rather than tuning.
Performance budgets are designed to prevent reaching that point silently.
What a Performance Budget Actually Is
A performance budget defines explicit limits on what the system is allowed to do. These limits can apply to different layers of the architecture: network payload, JavaScript execution time, number of requests, rendering milestones, or even third-party dependencies. The exact metrics matter less than the existence of enforced boundaries.
The key distinction is that a budget is enforced before regressions reach users. It shifts performance from a retrospective concern to a design-time and build-time constraint. When a change exceeds the budget, it forces a conversation: either the change is worth the cost, or something else must be removed or restructured.
Without this mechanism, performance discussions remain abstract. Everyone agrees speed is important, but no one is responsible for protecting it.
Budgets as Governance, Not Optimization
A common mistake is treating performance budgets as optimization tools. Teams define thresholds, fail builds, and then scramble to shave bytes or defer scripts without questioning why the budget was exceeded in the first place. This turns budgets into another technical hurdle rather than a governance mechanism.
Used correctly, budgets surface architectural pressure. They reveal where complexity is accumulating and which parts of the system are absorbing it. When a budget is consistently exceeded, it signals that the system's assumptions no longer hold. At that point, optimization is the wrong response. Re-architecting scope, flows, or responsibilities is often required.
Budgets do not eliminate trade-offs. They make trade-offs explicit.
Continuous Control vs One-Time Optimization
One-time optimization efforts create a false sense of security. After a performance sprint, metrics improve, stakeholders relax, and attention shifts elsewhere. Without ongoing control, the system resumes its natural trajectory toward complexity. Performance work becomes cyclical: audit, optimize, regress, repeat.
Continuous control replaces this cycle with steady pressure. Performance is monitored not to celebrate scores, but to detect drift. Changes are evaluated against constraints consistently, not only when problems are visible. This turns speed into a maintained property rather than a recurring emergency.
From an architectural perspective, continuous control is less about tooling and more about ownership. Someone must be responsible for saying when performance costs are justified — and when they are not.
Common Types of Performance Budgets
The table below outlines typical budget categories and what they actually control.
Budget type |
What it limits |
Architectural signal |
Page weight |
Total transferred data |
Content and media discipline |
JavaScript execution |
Main-thread workload |
Client responsibility scope |
Request count |
Network coordination |
Dependency and API design |
Rendering milestones |
Time to usable state |
Rendering and prioritization strategy |
Third-party scripts |
External execution |
Organizational boundary control |
Not every system needs all of these budgets. What matters is selecting the ones that reflect the system's biggest risks and enforcing them consistently.
Even well-architected systems require ongoing attention. Continuous site optimization ensures that performance remains aligned with architectural intent as content, dependencies, and traffic patterns evolve.
Performance Ownership as a System Requirement
Performance budgets fail when no one owns them. If exceeding a budget is treated as "someone else's problem," the constraint becomes symbolic. Effective systems assign clear responsibility: not necessarily to a single person, but to a role or process that has the authority to block changes when limits are violated.
This ownership must extend beyond engineering. Product, design, and content decisions all affect performance, and budgets should apply to all of them. When only developers are accountable, the system incentivizes workarounds rather than structural improvement.
Performance stays predictable when it is defended deliberately.
When Budgets Are Ignored
Ignoring performance budgets does not usually break a site immediately. It erodes it. Teams grow accustomed to minor regressions. Users adapt by lowering expectations or leaving quietly. Over time, speed stops being part of the product's identity and becomes a liability.
Recovering from this state is significantly more expensive than preventing it. Architectural cleanup, dependency removal, and redesigns under pressure cost far more than enforcing limits early.
Fast websites are not fast because they are optimized often.
They are fast because they are governed continuously.
9. Common Performance Anti-Patterns
Most slow websites are not the result of neglect. They are the result of good intentions applied without structural discipline. Teams care about speed, talk about speed, and even measure speed — but still make decisions that quietly undermine it.
One of the most common anti-patterns is treating performance as a phase. Speed is addressed during audits, sprints, or launches, then deprioritized once metrics improve. This creates a cycle where performance is periodically "fixed" rather than continuously protected. Each cycle leaves behind more complexity than before.
Another frequent failure is allowing responsibility for performance to fragment. Frontend teams optimize rendering, backend teams optimize APIs, designers optimize visuals, and marketing adds scripts independently. No one owns the behavior of the system as a whole. Performance degrades not because any one decision is wrong, but because no one is accountable for cumulative cost.
Third-party dependency sprawl is another recurring pattern. Tools are added because they promise insight, automation, or conversion gains, but rarely removed when their value diminishes. Over time, the main thread becomes crowded with work that does not directly serve users, and performance becomes hostage to external systems outside the team's control.
Finally, many teams overestimate the browser and underestimate coordination cost. Rich interactions, heavy abstractions, and dynamic layouts feel acceptable in isolation. At scale, they compete for the same limited resources. Performance collapses not under peak load, but under everyday use.
These anti-patterns persist because they feel reasonable locally. Architecturally, they are corrosive.
10. A Practical Framework for Building and Maintaining Fast Websites
Fast websites are not created through heroics. They are the result of systems designed to resist unnecessary complexity and governed to stay within explicit limits.
A practical performance framework starts with treating speed as a constraint, not a KPI. Constraints influence decisions automatically. When performance budgets exist, trade-offs are visible early. When they don't, complexity accumulates silently.
The second requirement is clarity of ownership. Someone — or some process — must have the authority to say no when performance costs outweigh value. Without this, speed becomes everyone's responsibility and no one's job.
The third principle is architectural alignment. Frontend rendering strategy, backend data flow, content structure, and dependency management must reinforce each other. When one layer compensates for another, performance becomes fragile. When layers align, speed emerges naturally.
Finally, fast systems are maintained, not preserved. Monitoring exists to detect drift, not to celebrate scores. Changes are evaluated against constraints continuously, not only when users complain. Performance remains predictable because deviation is noticed early and corrected deliberately.
Building a fast website is not about chasing perfect metrics.
It is about designing a system that behaves well by default — and continues to do so as it grows.
Want to discuss your project?
Share your vision with us, and we'll reach out soon to explore the details and bring your idea to life.


Conclusion
Your brand is what people say about you when you're not in the room.
— Jeff Bezos, founder of Amazon
Fast websites are not the outcome of a single optimization sprint. They are the result of a system that was designed to stay fast under growth. When performance is treated as a late-stage technical concern, teams end up fighting symptoms: compressing assets, deferring scripts, tweaking caching, chasing scores. Those actions can help, but they rarely hold, because the underlying architecture keeps producing the same failure modes as soon as the site evolves.
The central idea of performance architecture is simple: speed is an emergent property. It emerges from how responsibilities are distributed between server and client, how data is modeled and delivered, how rendering is sequenced, how assets and third parties are governed, and how change is controlled over time. If any layer is allowed to grow without constraints, the system will drift toward complexity, and complexity will eventually dominate performance.
This is why "fast" is not primarily a metric. It is a user experience: the feeling that the site responds immediately, remains stable while loading, and behaves predictably when users act. Technical measurements like Core Web Vitals matter because they reflect this experience under real-world conditions. But the mistake is treating them as goals instead of signals. When metrics are used diagnostically, they guide architectural decisions. When they are treated as targets, teams often end up gaming numbers while the system remains fragile.
The practical takeaway is that speed must be made non-optional. The only reliable way to do that is governance: explicit performance budgets, clear ownership, and decision rules that force trade-offs to be acknowledged early. Budgets don't just protect load time. They protect the system from silent accumulation — the slow creep of scripts, media weight, UI complexity, and coordination overhead that turns an initially fast site into a sluggish one.
If you want a website that stays fast, the path is not more tools. It's better constraints. Build with a rendering strategy that prioritizes early usefulness and interactivity. Design data flow to be predictable and shaped around consumption patterns rather than internal models. Treat assets and third-party dependencies as architectural decisions with explicit cost justification. Use metrics to detect drift and trigger structural correction, not as a scoreboard. And most importantly, make performance a shared responsibility across product, design, content, and engineering — because it is shaped by all of them.
Fast websites stay fast only when maintenance is treated as a continuous process. Without structured updates and review cycles, even strong architectures slowly drift toward complexity and degraded performance.
Performance architecture is ultimately a maturity marker. It reflects whether a team builds systems that scale gracefully, or systems that require continuous firefighting. When speed is designed in and governed continuously, it stops being fragile. It becomes repeatable — and that is what separates a fast launch from a fast website.
Performance problems don't start in code. They start when teams make decisions without treating speed as a constraint. Once performance is optional, every future feature makes the system slower — even if nobody breaks anything explicitly.